

OpenAI周二推出旗下迄今能力最强的两款小型模型GPT-5.4 mini与GPT-5.4 nano,以更低延迟和更低成本大幅缩小与旗舰模型的性能差距。GPT-5.4 mini在编程、推理、多模态理解及工具调用等核心维度全面超越上一代GPT-5 mini,运行速度提升逾2倍,并在SWE-Bench Pro等基准测试中接近体量更大的GPT-5.4。
GPT-5.4 nano则定位成本最低、延迟最短的轻量选项,仅通过API向开发者开放,专为数据分类、提取及简单编程子任务设计。
两款模型的推出,意在填补大模型在实时交互场景中因延迟过高而难以落地的空白,直接影响覆盖编程助手、AI代理系统及多模态应用等快速增长的商业市场。
mini面向消费端,nano专属API
GPT-5.4 mini今日起在OpenAI API、Codex平台及ChatGPT三大渠道同步上线。
GPT-5.4 mini的API定价为每百万输入token 0.75美元、每百万输出token 4.50美元,支持文本与图像输入、工具调用、函数调用、网页搜索、文件检索、计算机操控及技能扩展,上下文窗口达40万token。
在Codex平台,GPT-5.4 mini仅消耗GPT-5.4配额的30%,开发者处理简单编程任务的成本约降至旗舰模型的三分之一。Codex还支持将工作量委派给以GPT-5.4 mini运行的子智能体,使推理密度较低的任务自动落入更廉价的模型。
在ChatGPT端,Free与Go用户可通过"+"菜单选择"Thinking"功能使用GPT-5.4 mini;其余付费用户在GPT-5.4 Thinking触达速率上限后,该模型将作为自动降级备选项启用。
GPT-5.4 nano目前仅通过API供开发者调用,定价为每百万输入token 0.20美元、每百万输出token 1.25美元,为两款新模型中定价最低者。OpenAI表示,nano适合由高阶模型统筹调度、负责处理次要支撑任务的子智能体场景。
mini逼近旗舰,nano超越前代
从OpenAI公布的评测数据来看,GPT-5.4 mini在编程及多模态任务上的表现尤为突出。
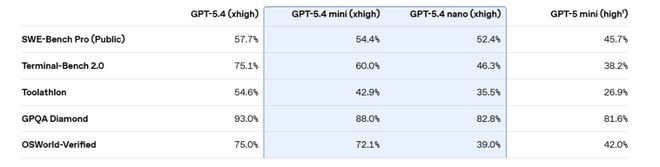
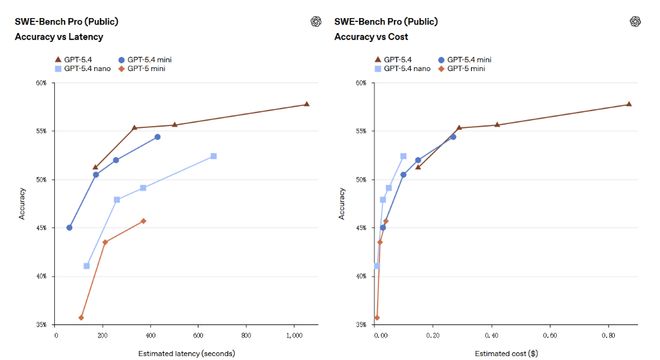
在编程基准SWE-bench Pro上,mini得分54.4%,与GPT-5.4的57.7%差距收窄至3.3个百分点,远高于GPT-5 mini的45.7%。

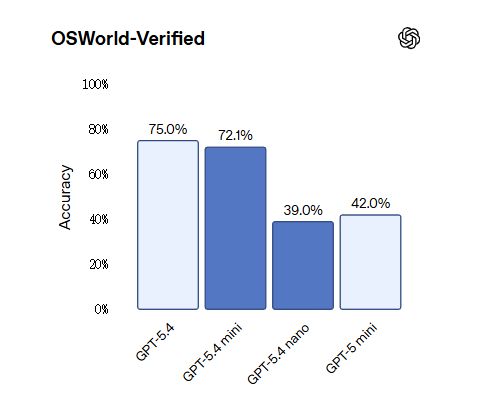
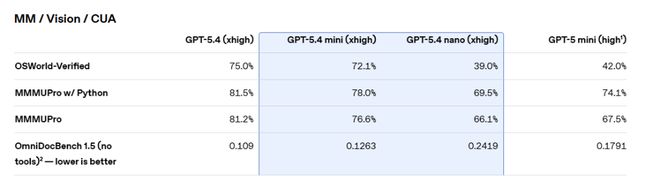
在计算机操控基准OSWorld-Verified上,mini以72.1%逼近GPT-5.4的75.0%,并大幅领先GPT-5 mini的42.0%。
工具调用能力方面,GPT-5.4 mini在τ2-bench电信测试中得分93.4%,较GPT-5 mini的74.1%提升显著。在通用智能测试GPQA Diamond中,mini得分88.0%,nano亦达82.8%,均超越GPT-5 mini的81.6%。

值得关注的是,GPT-5.4 nano在部分视觉任务中表现落后于GPT-5 mini,OSWorld-Verified得分39.0%低于后者的42.0%。但在编程及工具调用类任务上,nano仍较前代实现明显提升。
OpenAI表示,nano的设计优先级在于低延迟与低成本,而非全面性能,开发者在选型时需结合具体任务权衡取舍。
子智能体架构,多模型协作成产品设计新范式
OpenAI在发布材料中着重强调了两款新模型在多模型分层系统中的位置。
以其自研编程助手Codex为例,GPT-5.4负责规划、协调与最终判断,而GPT-5.4 mini子智能体则并行处理代码库检索、大文件审阅及辅助文档处理等粒度更细的子任务。
OpenAI表示,随着小型模型速度更快、功能更强大,开发者无需使用单一模型处理所有任务,而是可以构建系统,由大型模型负责决策,小型模型则快速大规模地执行任务。OpenAI称:
GPT-5.4 mini 是我们迄今为止针对这种工作流程最强大的小型模型。
这一架构对高并发的工作尤为关键,在编程助手、截图解析及实时图像理解等场景中,响应延迟直接影响产品体感,最优选择往往不是能力最强的模型,而是能够在速度、工具可靠性与任务表现之间取得最佳平衡的模型。
对开发者而言,GPT-5.4 mini与nano的发布意味着在不牺牲系统整体智能水平的前提下,大幅压降推理成本的路径进一步清晰。